
Phishing Doc Lures
Threat actors commonly use Microsoft Office documents with VBA macros for phishing attacks to infect an unexpecting end user.
To get the user to enable macros, the documents commonly contain image lures. Some claim the document is
- from an older version of office,
- encrypted, or
- protected.
Initial Attempt at OCR
InQuest wrote a blog post showing some common lures contained in malicious documents.
One of the methods security researchers have attempted to detect documents with these lures, is through Optical Character Recognition.
OCR is very good if the images are well formed and the threat actor hasn’t taken steps to confuse OCR systems. Some methods to make OCR harder are
- lowering the image resolution,
- introducing noise into the image, or
- using similar colors for text and background.
Below is an image lure used by Emotet.
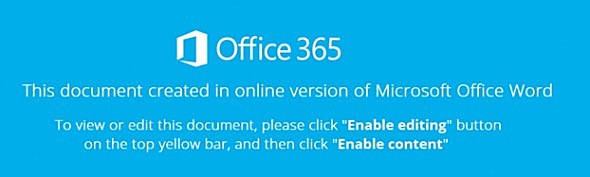
I use pytesseract for OCR to attempt to extract the text.
# quick script for using OCR
import sys
import pytesseract
from PIL import Image
img = Image.open(sys.argv[1])
print pytesseract.image_to_string(img) # some images are too blurryBelow is the result of using OCR on the above image.
image_ocr.py 110eadfb5f462cfd22bfbcb0d8cc0b218cdb720a357997e4afeb636491f8ffaa_image.png
ÿIOfiiaeSGS
mmwnmmummm
“mumummmmwmm
autumn-magnum“Unfortunately, OCR was not able to recognize anything. This is likely due to the noise and blurring near the characters.

OCR With Pre-processed Image
My first thought was to use some pre-processing before passing the image to OCR. I have worked on something similar in the past, and so decided to take a similar approach.
I used some pre-processing to separate the image into a two color image.

image_ocr.py 110eadfb5f462cfd22bfbcb0d8cc0b218cdb720a357997e4afeb636491f8ffaa_mod_image.png
fl ,A ,
Ulhoirmt: 3m;
-2½.- m m-yun ‘ mi v gum-L: ‘/:)‘nm- a“ mlwwmIt looks even worse. I believed I had the right idea, but not the right approach. I thought maybe if I was able to determine that background color I could then adjust my method.
Image.open('edit.jpg')
colors = Counter(i.getdata())
print colors[max(colors, key=colors.get)]
# 124104
print i.size
# (707, 244)
print 707*244
# 172508
print 124104/172508.0
# 0.7194101143135391Turns out that 71%+ is all one color, the light blue. I thought I could just list the highest used colors and only use the top 4.
t = [(0, 174, 234), (1, 174, 234), (0, 175, 234), (0, 174, 235)]
for x in range(i.width):
for y in range(i.height):
if i.getpixel((x,y)) not in t:
i.putpixel((x,y), (0, 174, 234))
i.save('edit_4_colors.jpg')
OCR with K-Means Clustering
Turns out the top 4 colors were all background, just slightly different shades. I needed a way to combine these groups no matter the color. So I turned to clustering.
# Modified from code by Peter Hansen, https://stackoverflow.com/questions/3241929/python-find-dominant-most-common-color-in-an-image
from __future__ import print_function
import binascii
import struct
from PIL import Image
import numpy as np
import scipy
import scipy.misc
import scipy.cluster
import sys
NUM_CLUSTERS = 2
print('reading image')
im = Image.open(sys.argv[1])
ar = np.asarray(im)
shape = ar.shape
ar = ar.reshape(scipy.product(shape[:2]), shape[2]).astype(float)
print('finding clusters')
codes, dist = scipy.cluster.vq.kmeans(ar, NUM_CLUSTERS)
print('cluster centres:\n', codes)
vecs, dist = scipy.cluster.vq.vq(ar, codes) # assign codes
counts, bins = scipy.histogram(vecs, len(codes)) # count occurrences
index_max = scipy.argmax(counts) # find most frequent
peak = codes[index_max]
colour = binascii.hexlify(bytearray(int(c) for c in peak)).decode('ascii')
print('most frequent is %s (#%s)' % (peak, colour))
import imageio
c = ar.copy()
for i, code in enumerate(codes):
c[scipy.r_[scipy.where(vecs==i)],:] = code
imageio.imwrite('clusters.png', c.reshape(*shape).astype(np.uint8))
print('saved clustered image')I used k-means clustering to group the pixels into 5 clusters. I then went through each cluster setting the pixel to the avg color for that cluster. This reduces the colors in the image by using the actual colors in the image and not an arbitrary threshold.


image_ocr.py
flOfi'IGBBSS
M»mmmmmuwmw
nmummmmmwuw
mmmmu.umnmu-IuStill no luck, but I decided to try 2 clusters, to get the most contrast possible.
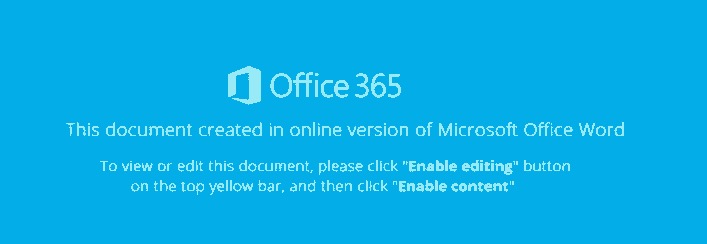
image_ocr.py
I] Office 365
This document created In online version of Microsoft Office Word
To View Dr edn this document, please (llck "En-bl: edit n5" button
on me [up yellow bar, and men cnck "Enable :onzem"YES!!! Progress. It still can’t recognize everything but we can clearly see indicators of a lure. Lets see if we can improve this.
OCR With Further Improvements
I looked into maybe trying to use bezier curves to estimate the chars and then redraw them somewhere else and pass that to the OCR.
Wasn’t able to get anywhere, but I remembered some one on Stack Overflow mentioning to make the image bigger before OCR to help improve the output.
So I decided to give this a try and
- resized the image to 3 times its normal size,
- clustered on colors,
- reduced colors to 2 tones, and
- passed to OCR.

image_ocr.py
I] Office 365
This document created in online version of Microsoft Office Word
To view or edit this document, please click "Enable editing" button
on the top yellow bar, and then click "Enable content"And it WORKED! It improved the output drastically and now you can clearly read the lure text.
Here it is running on a lure from Zloader.
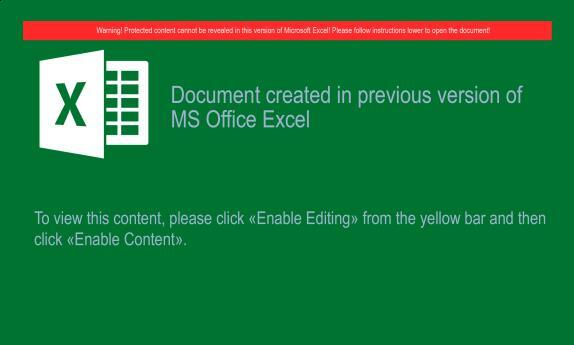
image_ocr.py fig½ 4.png
X Document created in previous version of
MS Office Excel
To wew W5 comer“ please CNEK «Enable Edmngn (rem me yellow Darand than
ÿluck uEnabVe Cement»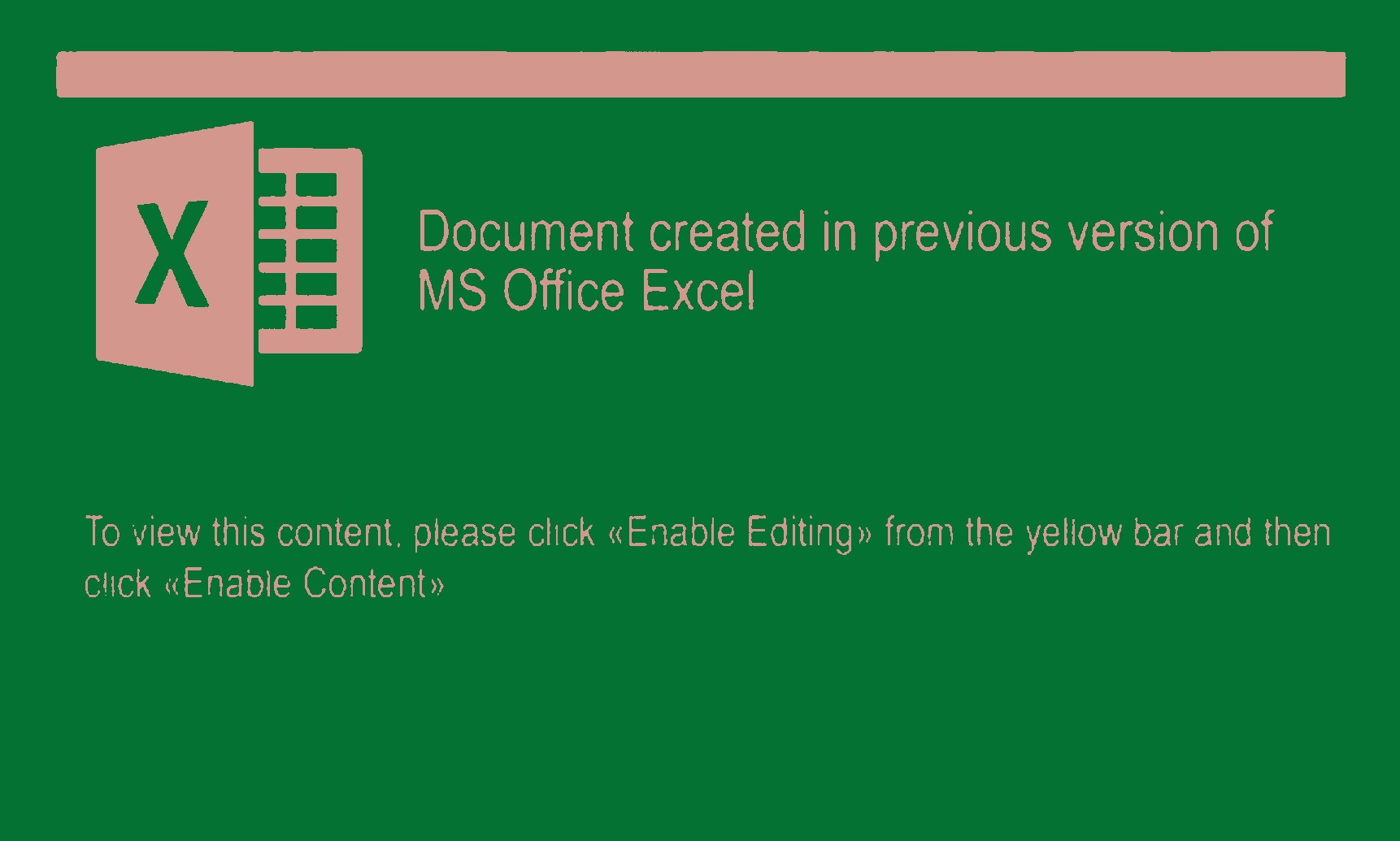
image_ocr.py clusters.png
X Document created in previous version of
MS Office Excel
To view this content. please click «Enable Editing» from the yellow bar and then
click «Enable Content»Results
I have updated my tool, doctools, created to extract images from DOC files. It still needs to be expanded to DOCX and Excel formats. Below is the output from running it on a recent Emotet sample.
python extract_img.py -f ../Z_ZG9552902820ZM.doc -o
most frequent is [254.55600768 254.74310052 254.55694112] (#fefefe)
I] Office 365
This document only available for desktop or laptop versions of Microsoft Office Word.
To open the document, follow these steps:
Click Enable editing button from the yellow bar above,
Once you have enabled editing, please click Enable content button.
Suspious words found in extracted text
['image sha256 hash is: 07e0449189d63cb013e70a44d60411965cf32e6d5880cb7c2ad64470130b453e']Below is an example of running OCR on an image with a multicolored background. Image from Inquest a1cd9613ecd69483134f09d9794965396f224579feeb6aec58d4c11b76b19344
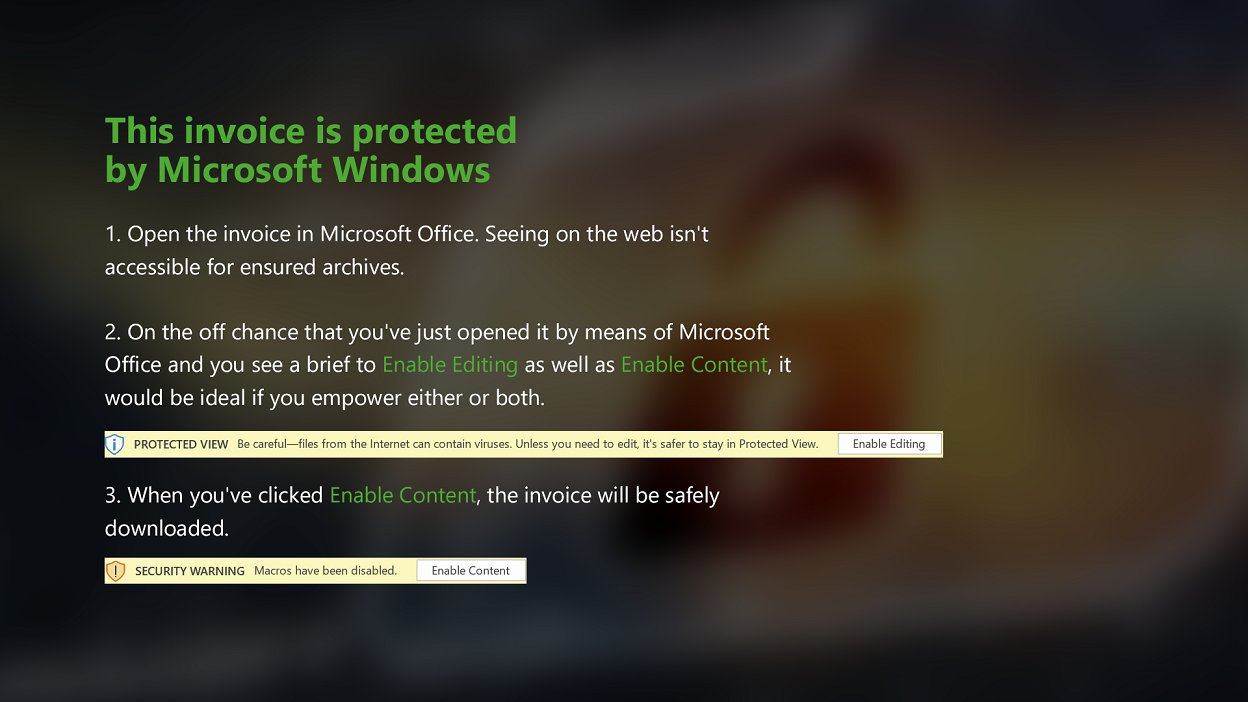
malspam@malspam:~/malspam_analytics/year=2020/month=04$ python image_ocr.py EX820fYXQAE059F\?format\=jpg
This invoice is protected
by Microsoft Windows
1. Open the invoice in Microsoft Office. Seeing on the web isn't
accessible for ensured archives.
2. On the off chance that you'vejust opened it by means of Microsoft
Office and you see a brief to Enable Edmng as well as Enable Comom, it
would be ideal if you empower either or both
rmricrmwav >wM~Mm m mm. H . r 'l'it'n‘w mum“. in mm.
3. When you‘ve clicked Enable Conlem, the invoice will be safely
downloaded.
xiumnvmwlluc r. :‘mrlyl.aprcmira.l.n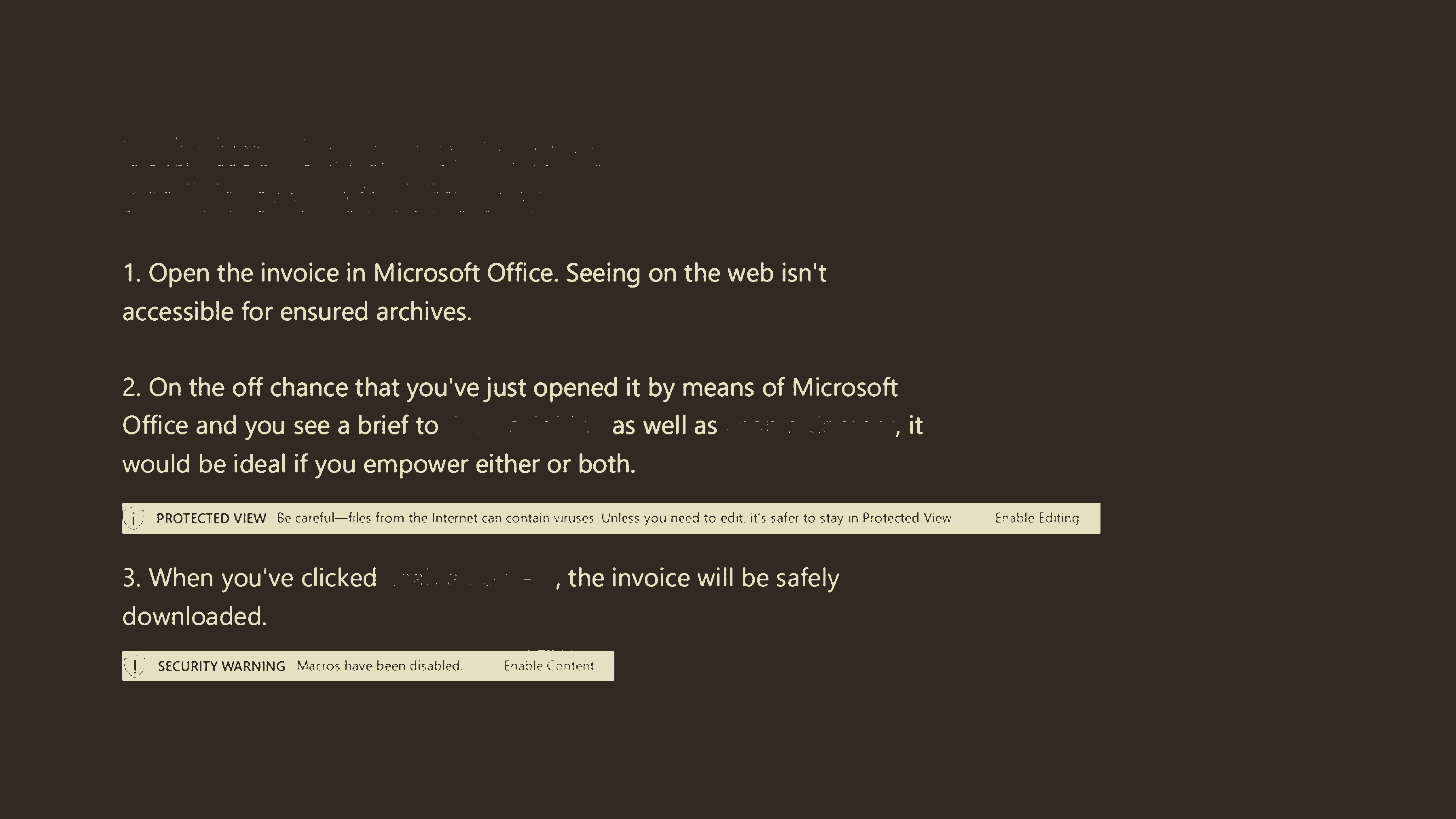
image_ocr.py clusters.png
1. Open the invoice in Microsoft Office. Seeing on the web isn't
accessible for ensured archives.
2. On the off chance that you'vejust opened it by means of Microsoft
Office and you see a brief to ' i ' i as well as i ‘ ' , it
would be ideal if you empower either or both.
i PROTECTED VIEW Se careful—files from the Internet can contain ‘-'lrUSCS Unless you need to edit. it‘s. safer to stay In Protected Vic-w Enable Editing
3. When you‘ve clicked 7 . e ,the invoice will be safely
downloaded.
Cl," SECURITY WARNING Memos. have been disabled, Enable ("mm